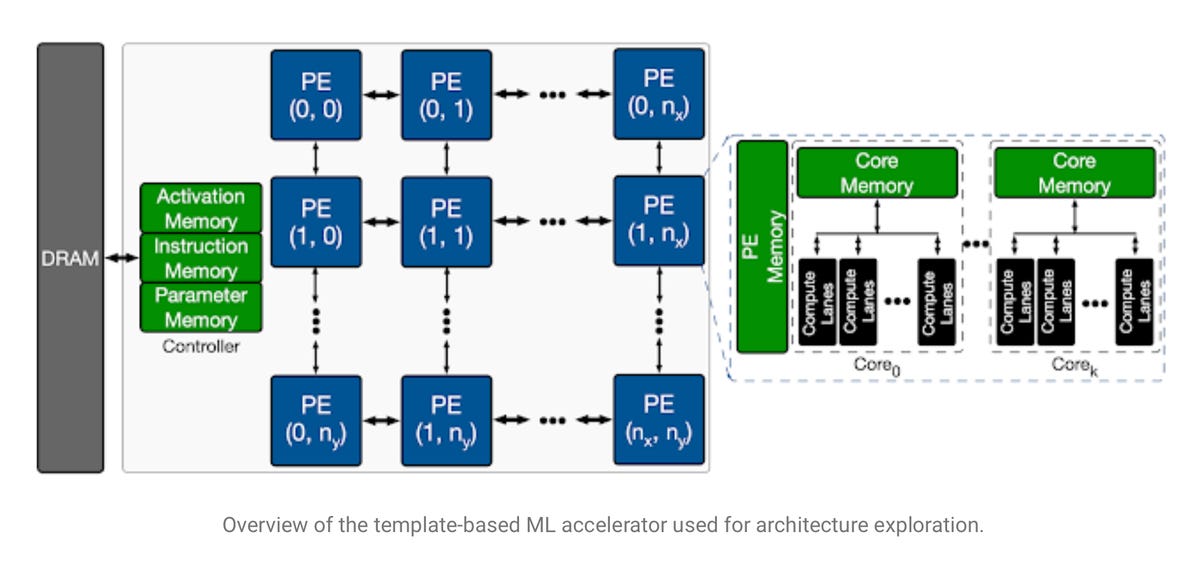
The so-called search space of an accelerator chip for artificial intelligence, meaning, the functional blocks that the chip's architecture must optimize for. Characteristic to many AI chips are parallel, identical processor elements for masses of simple math operations, here called a "PE," for doing lots of vector-matrix multiplications that are the workhorse of neural net processing.
Yazdanbakhsh et al.A year ago, ZDNet spoke with Google Brain director Jeff Dean about how the company is using artificial intelligence to advance its internal development of custom chips to accelerate its software. Dean noted that deep learning forms of artificial intelligence can in some cases make better decisions than humans about how to lay out circuitry in a chip.
This month, Google unveiled to the world one of those research projects, called Apollo, in a paper posted on the arXiv file server, "Apollo: Transferable Architecture Exploration," and a companion blog post by lead author Amir Yazdanbakhsh.
Apollo represents an intriguing development that moves past what Dean hinted at in his formal address a year ago at the International Solid State Circuits Conference, and in his remarks to ZDNet.
In the example Dean gave at the time, machine learning could be used for some low-level design decisions, known as "place and route." In place and route, chip designers use software to determine the layout of the circuits that form the chip's operations, analogous to designing the floor plan of a building.
In Apollo, by contrast, rather than a floor plan, the program is performing what Yazdanbakhsh and colleagues call "architecture exploration."
The architecture for a chip is the design of the functional elements of a chip, how they interact, and how software programmers should gain access to those functional elements.
For example, a classic Intel x86 processor has a certain amount of on-chip memory, a dedicated arithmetic-logic unit, and a number of registers, among other things. The way those parts are put together gives the so-called Intel architecture its meaning.
Asked about Dean's description, Yazdanbakhsh told ZDNet in email, "I would see our work and place-and-route project orthogonal and complementary.
"Architecture exploration is much higher-level than place-and-route in the computing stack," explained Yazdanbakhsh, referring to a presentation by Cornell University's Christopher Batten.
"I believe it [architecture exploration] is where a higher margin for performance improvement exists," said Yazdanbakhsh.
Yazdanbakhsh and colleagues call Apollo the "first transferable architecture exploration infrastructure," the first program that gets better at exploring possible chip architectures the more it works on different chips, thus transferring what is learned to each new task.
The chips that Yazdanbakhsh and the team are developing are themselves chips for AI, known as accelerators. This is the same class of chips as the Nvidia A100 "Ampere" GPUs, the Cerebras Systems WSE chip, and many other startup parts currently hitting the market. Hence, a nice symmetry, using AI to design chips to run AI.
Given that the task is to design an AI chip, the architectures that the Apollo program is exploring are architectures suited to running neural networks. And that means lots of linear algebra, lots of simple mathematical units that perform matrix multiplications and sum the results.
The team define the challenge as one of finding the right mix of those math blocks to suit a given AI task. They chose a fairly simple AI task, a convolutional neural network called MobileNet, which is a resource-efficient network designed in 2017 by Andrew G. Howard and colleagues at Google. In addition, they tested workloads using several internally-designed networks for tasks such as object detection and semantic segmentation.
In this way, the goal becomes, What are the right parameters for the architecture of a chip such that for a given neural network task, the chip meets certain criteria such as speed?
The search involved sorting through over 452 million parameters, including how many of the math units, called processor elements, would be used, and how much parameter memory and activation memory would be optimal for a given model.
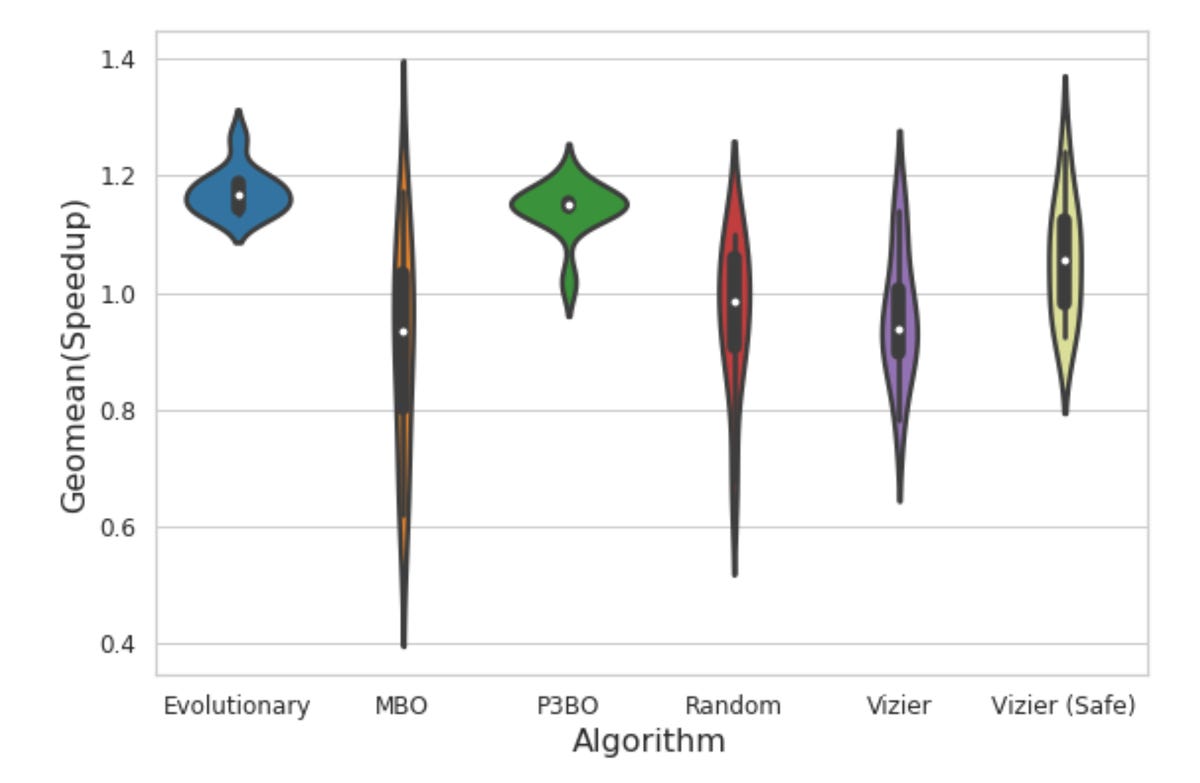
The virtue of Apollo is to put a variety of existing optimization methods head to head, to see how they stack up in optimizing the architecture of a novel chip design. Here, violin plots show the relative results.
Yazdanbakhsh et al.Apollo is a framework, meaning that it can take a variety of methods developed in the literature for so-called black box optimization and it can adapt those methods to the particular workloads, and compare how each method does in terms of solving the goal.
In yet another nice symmetry, Yazdanbakhsh employ some optimization methods that were actually designed to develop neural net architectures. They include so-called evolutionary approaches developed by Quoc V. Le and colleagues at Google in 2019; model-based reinforcement learning, and so-called population-based ensembles of approaches, developed by Christof Angermueller and others at Google for the purpose of "designing" DNA sequences; and a Bayesian optimization approach.
Hence, Apollo contains main levels of pleasing symmetry, bringing together approaches designed for neural network design and biological synthesis to design circuits that might in turn be used for neural network design and biological synthesis.
All of these optimizations are compared, which is where the Apollo framework shines. Its entire raison d'être is to run different approaches in a methodical fashion and tell what works best. The Apollo trials results detail how the evolutionary and the model-based approaches can be superior to random selection and other approaches.
But the most striking finding of Apollo is how running these optimization methods can make for a much more efficient process than brute-force search. They compared, for example, the population-based approach of ensembles against what they call a semi-exhaustive search of the solution set of architecture approaches.
What Yazdanbakhsh and colleagues saw is that a population-based approach is able to discover solutions that make use of trade-offs in the circuits, such as compute versus memory, that would ordinarily require domain-specific knowledge. Because the population-based approach is a learned approach, it finds solutions beyond the reach of the semi-exhaustive search:
P3BO [population-based black-box optimization] actually finds a design slightly better than semi-exhaustive with 3K-sample search space. We observe that the design uses a very small memory size (3MB) in favor of more compute units. This leverages the compute-intensive nature of vision workloads, which was not included in the original semi-exhaustive search space. This demonstrates the need of manual search space engineering for semi-exhaustive approaches, whereas learning-based optimization methods leverage large search spaces reducing the manual effort.
So, Apollo is able to figure out how well different optimization approaches will fare in chip design. However, it does something more, which is that it can run what's called transfer learning to show how those optimization approaches can in turn be improved.
By running the optimization strategies to improve a chip by one design point, such as the maximum chip size in millimeters, the outcome of those experiments can then be fed to a subsequent optimization method as inputs. What the Apollo team found is that various optimization methods improve their performance on a task like area-constrained circuit design by leveraging the best results of the initial or seed optimization method.
All of this has to be bracketed by the fact that designing chips for MobileNet, or any other network or workload, is bounded by the applicability of the design process to a given workload.
In fact, one of the authors, Berkin Akin, who helped to develop a version of MobileNet, MobileNet Edge, has pointed out that optimization is product of both chip and neural network optimization.
"Neural network architectures must be aware of the target hardware architecture in order to optimize the overall system performance and energy efficiency," wrote Akin last year in a paper with colleague Suyog Gupta.
ZDNet reached out to Akin in email to ask the question, How valuable is hardware design when isolated from the design of the neural net architecture?
"Great question," Akin replied in email. "I think it depends."
Said Akin, Apollo may be sufficient for given workloads, but what's called co-optimization, between chips and neural networks, will yield other benefits down the road.
Here's Akin's reply in full:
There are certainly use cases where we are designing the hardware for a given suite of fixed neural network models. These models can be a part of already highly optimized representative workloads from the targeted application domain of the hardware or required by the user of the custom-built accelerator. In this work we are tackling problems of this nature where we use ML to find the best hardware architecture for a given suite of workloads. However, there are certainly cases where there is a flexibility to jointly co-optimize hardware design and the neural network architecture. In fact, we have some on-going work for such a joint co-optimization, we are hoping that can yield to even better trade-offs…
The final takeaway, then, is that even as chip design is being affected by the new workloads of AI, the new process of chip design may have a measurable impact on the design of neural networks, and that dialectic may evolve in interesting ways in the years to come.
The Link LonkMarch 01, 2021 at 05:05AM
https://ift.tt/2O7b5C7
Google’s deep learning finds a critical path in AI chips - ZDNet
https://ift.tt/2RGyUAH
Chips













